My paper with Adam Callahan on the almost power-law behavior of the type-token ratio in literary texts has been submitted for publication and is available here:callahan_davis_heavy_tails_final
In this paper we look in some detail at the behavior of the average number of new words in the first  words of a text, as a function of . Consider replacing each word in a text by a 1 if that word has not appeared previously in the text, and by a 0 if it has appeared previously. The type-token ratio
words of a text, as a function of . Consider replacing each word in a text by a 1 if that word has not appeared previously in the text, and by a 0 if it has appeared previously. The type-token ratio  is the average of the 1’s and 0’s up to . The sequences of 1’s and 0’s we get this way are not independent, and is not equivalent to a sequence of Bernoulli trial. The behavior of as a function of is that it is almost described by a power law. Basically, a regression of
is the average of the 1’s and 0’s up to . The sequences of 1’s and 0’s we get this way are not independent, and is not equivalent to a sequence of Bernoulli trial. The behavior of as a function of is that it is almost described by a power law. Basically, a regression of  on
on 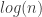 gives a straight line with, typically,
gives a straight line with, typically, 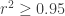 . This means there are constants
. This means there are constants  such that
such that 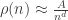 . When we plot
. When we plot 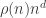 we should get, approximately, a constant. However we do not. Typically we get a plot that, as a function of , increases relatively rapidly to a maximum and then decreases very slowly.
we should get, approximately, a constant. However we do not. Typically we get a plot that, as a function of , increases relatively rapidly to a maximum and then decreases very slowly.
A real-valued function  of a positive integer variable is slowly varying if
of a positive integer variable is slowly varying if  as
as 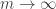 , for some number
, for some number  . (This is a “soft analysis” definition in Terry Tao’s sense, I believe. In the applications we have in mind it would definitely help to make this a “hard analysis” definition).
. (This is a “soft analysis” definition in Terry Tao’s sense, I believe. In the applications we have in mind it would definitely help to make this a “hard analysis” definition).
Not only, is a slowly varying function, but  – with
– with  as above – has a variance that is slowly varying and decaying to 0. We call functions that are slowly varying with a variance that decays to 0 as a power function, ultra-slowly varying. So what we find for literary texts of a variety of lengths, languages and genres, is that there is an index (dependent on the text) such that is ultra-slowly varying. If the ultra-slowly varying function were a constant we would have a genuine power law, but it isn’t and we don’t.
as above – has a variance that is slowly varying and decaying to 0. We call functions that are slowly varying with a variance that decays to 0 as a power function, ultra-slowly varying. So what we find for literary texts of a variety of lengths, languages and genres, is that there is an index (dependent on the text) such that is ultra-slowly varying. If the ultra-slowly varying function were a constant we would have a genuine power law, but it isn’t and we don’t.
We find that for the literary texts we examined, there is a point in the text, which we call a turn-over point, beyond which the type-token ratio is very well described by a power law (typically,  ) and before which, is better described as a function of the form
) and before which, is better described as a function of the form 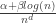 .
.
In this paper we also consider the relative frequency of occurrence of a word in the first words of a text as an estimate of the word’s probability of occurrence in the text, and consider the Shannon entropy  of the first words of text. Typically, increases logarithmically with .
of the first words of text. Typically, increases logarithmically with .
See also: Physics of Text.

